
Mit Methoden des Text Mining den Text inhaltlich erfassen und interpretieren
Unter Text Mining versteht man die Verarbeitung und Analyse von Textdaten, um mittels linguistischer und statistischer Verfahren Muster und unbekannte Informationen aus Dokumenten zu erschließen und für den Nutzer aufzubereiten. Anderes gesagt, geht es um einen Prozess der Wertschöpfung aus großen Mengen unstrukturierter Daten. Text Mining hat das Ziel die Daten, welche in Textform vorliegen, zu strukturieren und die dimensionalen Ausprägungen zu reduzieren. Damit werden die Voraussetzungen geschaffen, um weitergehende Analysen durchzuführen. Hierfür werden Methoden der Textnormalisierung und der Dimensionsreduzierung angewendet. Die verwendeten Algorithmen sind vielfältig und komplex. Der Text Mining-Prozess kann in sechs Schritte unterteilt werden [2]:
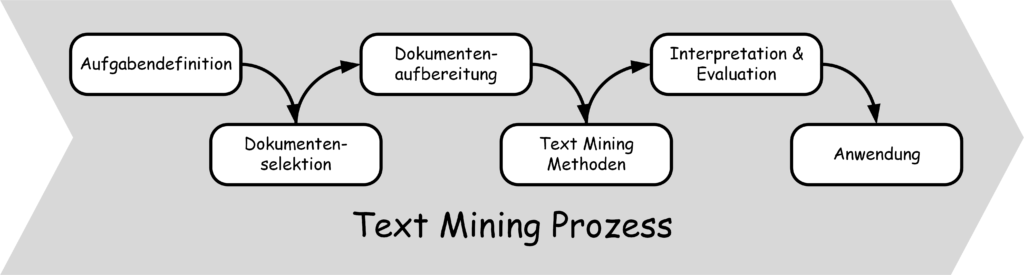
Bild 1: Teilschritte des Text Minings, Quelle: Coners, A., & Matthies, B.: Textanalyse im Controlling, 2015, Vahlen: München
- Aufgabendefinition: In diesem Schritt werden die Aufgaben-, Problemstellung und klare Ziele festgelegt, welche man mittels Text Mining umsetzen bzw. erreichen möchte.
- Dokumentenselektion: Ausgehend aus den festgelegten Zielen, werden die Dokumente ausgewählt, welche analysiert werden sollen.
- Dokumentenaufbereitung: Da die Dokumente meist in unterschiedlichen Formaten und Qualität vorliegen, erfolgt in diesem Schritt die Datenaufbereitung. Dieser Schritt schafft die Voraussetzungen, dass die Texte mit den Algorithmen verarbeitet werden können. Texte werden dazu zum Beispiel in Wortlisten überführt.
- Methoden: In diesem Schritt erfolgt die eigentliche Anwendung der Text Mining-Methoden. Textkategorisierung, Clustering und Sentiment-Analyse sind die drei gängigen Methoden.
- Interpretation und Evaluation: Die gewonnenen Ergebnisse werden anschließend unter dem Gesichtspunkt der Lösungsrelevanz für eine konkrete Problemstellung interpretiert und evaluiert.
- Anwendung: Die aus dem Schritt Interpretation und Evaluation erhaltenen Ergebnisse können nun für fallspezifische Entscheidungen eingesetzt werden.
Im Prozess des Text Minings werden zahlreiche Methoden angewendet. Die Methoden des Text Minings sind an die klassischen Verfahren des Data Minings angeknüpft:
- Klassifikation
- Abhängigkeitsanalyse
- Information Extraction
- Information Retrieval
- Natural Language Processing
- Clustering
- Summarization
Neben der theoretischen Bedeutung ist dieses Thema auch längst in der Praxis der Softwareentwicklung angekommen. Alltägliche Programme können schrittweise um diese Fähigkeiten erweitert werden. Ein einfaches Anwendungsbeispiel ist das Erkennen von Zeit- und Ortsangaben in einem Text, zum Beispiel einer E-Mail, um diese für die weitere Verarbeitung durch die Nutzerinnen oder Nutzer vorzuschlagen. Ebenso kann es hilfreich sein, den Tenor und das Hautthema aus einem sehr umfassenden Text in wenigen Augenblicken zu erfassen. Auf der Suche nach einer Problemlösung müssen oft viele Texte nach der passenden Information durchforstet werden. Ein intelligenter Suchalgorithmus kann große Textmengen in kürzester Zeit durchsuchen und damit eine Vorauswahl vornehmen.
Text Mining findet weiter praktische Anwendungsfelder in verschiedenen Bereichen:
- Digitale Bibliotheken: Um Muster und Trends aus einer großen Anzahl von Ressourcen bzw. Texten zu ermitteln.
- Forschung: Verwendung zum Auffinden von Forschungsarbeiten und von relevantem Material innerhalb eines thematischen Kontexts.
- Marketing: Textanalyse auf Webseiten mit dem Ziel Inhalten anhand von Schlüsselwörtern abzuleiten. Auf der Basis dieser Informationen können Unternehmen themen- und zielgruppengerechte Werbung schalten
- Social Media: Text Mining dient der Analyse von Texten, Meldungen und Posts. In Verbindung mit Likes und Verknüpfungen können Reaktionen der Nutzer analysiert und Trends erkannt werden.
- Gesundheitsbranche: Mittels Text Mining kann nach bestimmten Informationen und Zusammenhängen in einer großen Anzahl textueller und numerischer Daten, zum Beispiel Aufzeichnungen über Patienten, Krankheiten, Medikamente, Symptome und Behandlungen von Krankheiten, etc. suchen.
- Business Intelligence: Unternehmen können mittels Text Mining ihre Kunden und Konkurrenten analysieren und somit bessere Entscheidungen treffen.
- Rechtswissenschaften: Im juristischen Umfeld kann man umfassende Sammlungen von gerichtlichen Entscheidungen auf eine mögliche Relevanz zum eigenen Text untersuchen und damit die Bearbeitungszeit verkürzen
- Politikwissenschaften: Es können Transkripte von Reden und Gesprächsprotokolle untersucht und verschiedene Fragen beantwortet werden.
- Spam-Filterung: Texte können automatisch aussortiert werden, wenn diese höchstwahrscheinlich unnatürliche Sprache oder Inhalte mit geringem Wert enthalten.
Links und Literatur
[1] https://www.enzyklopaedie-der-wirtschaftsinformatik.de/lexikon/technologien-methoden/text-mining
[2] https://wiki.hslu.ch/controlling/Text_Mining
[3] http://www.wi.hs-wismar.de/~cleve/vorl/projects/da/13-Master-Seidel.pdf